These are not edge cases. They are the new core of building products responsibly.
When a recommendation becomes a liability
A team adds an AI recommendation layer to help users triage issues faster. Instead of reviewing everything manually, the product surfaces a suggested next step. It reduces noise. Users love it.
Then one user trusts it a little too much. They delay action resulting in escalated issue. A contractual SLA is breached.
Suddenly the conversation is no longer about whether the feature is useful. It is about who is responsible. Product points at Engineering. Engineering points at the model. There is no clear answer because nobody asked the right question upfront.
The right question was not “is the model good enough?” The model was fine.
The missing question was: What happens when a user trusts the system completely, in a situation we never designed for?
Accuracy is necessary. It is not enough.
Asking whether the model is accurate is not the wrong debate. It is the right starting point. You absolutely need to know how the model performs or how often it fails.
But accuracy only is not enough. Accuracy tells you how the model behaves in aggregate. It tells you nothing about what happens at the boundary — when the output is confidently wrong and the user has no way to tell the difference.
A great model can still cause real harm when it meets undefined governance. When nobody decided how uncertainty should be communicated. When the design made a suggestion look like a fact.
That is the boundary question. And it is a genuinely different question from model quality.
When one function dominates, the product breaks differently
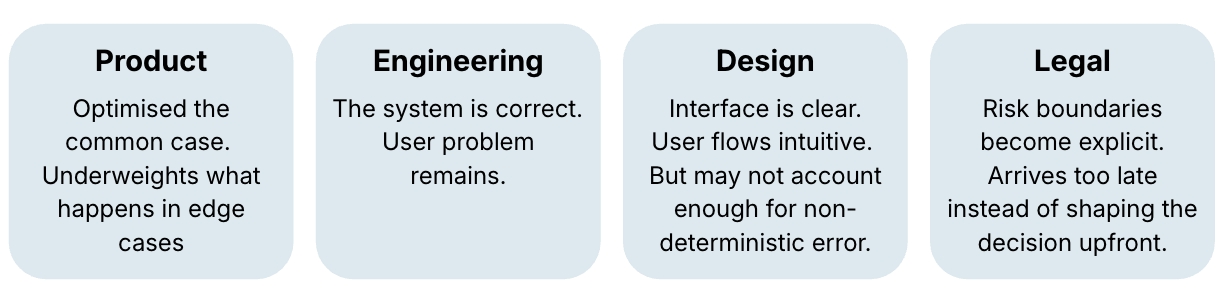
AI features tend to reflect who led them. And every function, leading alone, has a blind spot.
When Product leads, things get cleaner and faster. But product thinking is built for the typical user. It misses the edge — the person who trusts the recommendation at exactly the wrong moment, in exactly the wrong context. Smoother is not the same as safer.
When Engineering leads, the system gets more cautious about where probabilistic behavior is allowed. Good. But rigour without usability doesn’t solve the user problem. You can build something technically correct that leaves the actual problem unanswered.
Each function has a blindspot
When Design leads, the interface gets clearer and more intuitive. But design thinking is focused on comprehension — can the user read this, find this, act on this. It doesn't naturally ask a different question: Is this what the system knows or what it thinks? That distinction is easy to miss in a design review and very hard to explain after an incident.
When Legal and Compliance show up just before product launch, the organisation finds out too late that a useful feature also creates exposure. The question becomes “How do we add a disclaimer?” when it should have been “Should this layer be probabilistic at all?”
No single function sees the full picture. The failure modes are different. The protection has to be shared.
Four layers, one rule
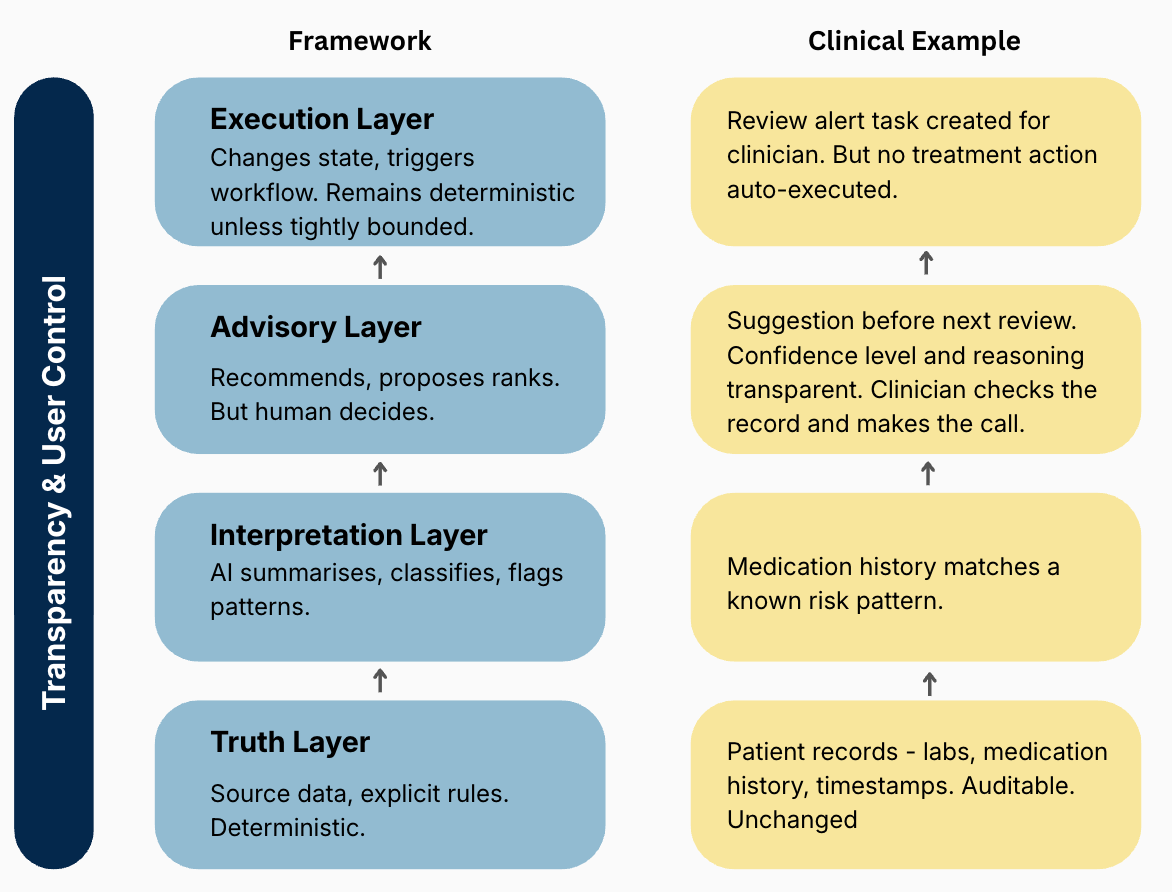
Not all parts of a product carry the same risk. The mistake is treating AI as a single capability and spreading it evenly. A more useful way to think about it is through layers, each with a different tolerance for uncertainty.
The Truth layer is the foundation. Source data, user input, explicit rules, system state. This stays deterministic. No AI interpretation, no probabilistic behaviour. Users must always be able to come back here and verify what is actually true.
The Interpretation layer is where AI earns its first real role — summarising, classifying, grouping, making complexity easier to navigate. Probabilistic behaviour is fine here, as long as the output stays traceable back to the truth.
The Advisory layer is where the product starts recommending, proposing, surfacing likely answers. This is where most of the value lives. But it is also where the risk climbs fast. The moment users start acting on AI output, the design bar changes completely.
The Execution layer is where the system acts — triggers workflows, changes state, sends messages on your behalf. This should stay deterministic unless you have defined, and explicitly agreed on, very tight boundaries around where AI can operate.
Running through all four — not as a layer itself, but as the condition that makes the others trustworthy, is Transparency & User Control. Users need to know what is original, what is inferred, what is proposed, and what they can still change - they remain in control.
Transparency is not a design choice. It is what makes probabilistic AI usable.
How this looks like in practice
Take a clinical decision support tool used by a hospital triage team. Nurses and junior doctors are working through a queue. The system has access to patient history, recent vitals, lab results, current medication. It is trying to help them move faster without missing something critical.
The patient record stays untouched. Every data point is sourced, timestamped, auditable. That is the truth layer — nobody interprets it away. If something looks wrong, you go back to the source.
The model then reads across that data and flags patterns, e.g. these inflammation markers combined with this medication history have preceded serious complications in similar patients. It is not telling anyone what to do. It is making a connection that a tired clinician at a night shift might have missed. That is the interpretation layer.
The product then surfaces a recommendation: this patient may need escalation before the next scheduled review. The system shows why the case was flagged, which signals support the recommendation, and what information may be incomplete. The clinician checks the record and makes the call. That is the advisory layer — the human still decides, but with better information.
Some things the system could automate — sending an alert, flagging for senior review, updating the patient status. But in this context, those actions stay deterministic and tightly defined. The system can trigger an alert when vitals cross a hard threshold. It cannot decide on its own that a patient needs escalation based on a probabilistic read. That boundary is not a technical limitation. It is a design choice about where AI is allowed to act. That is the execution layer.
Running through all of it is transparency. The clinician can see why the system flagged this patient — which data points, which pattern. It’s not a black box recommendation, but a visible chain of reasoning. That is what makes it possible to trust the output enough to act on it, or to override it with confidence.
A few rules to keep in mind
Not every layer should be probabilistic. The closer you are to truth, control, or irreversible consequence, the more deterministic you need to stay. AI does not belong everywhere just because it technically can go everywhere.
Let the cost of being wrong set the constraints. In some flows a weak recommendation creates minor friction. In others it causes huge escalations, contractual exposure, or trust that takes a long time to rebuild. The downside should determine the decision.
A recommendation that looks like a decision is a design failure.
There is a real difference between helping users see more clearly and quietly reshaping what they see. Summarising, grouping, flagging — that is interpretation. Suppressing, reordering, deciding what matters — that is something else. The line between them is easy to miss in a design review and very hard to explain after an incident.
Transparency and user control are not nice to have. They are the product. Without them, even well-designed AI can mislead. With them, even imperfect AI can be genuinely useful.
Define the boundary before launch. What is the AI allowed to influence? How is uncertainty communicated? Where are the override paths? These need explicit answers — not team assumptions that nobody ever wrote down.
Closing Thoughts
The maturity test for AI in product is not how many features you can ship.
It is whether your organisation can answer — before anything goes wrong — where AI helps, where it stays advisory, and where it should not decide at all. Who defined that line? Who signed off on it?
Those are not model questions. They are leadership questions.
The teams that answer them early are not being slow or overcautious. They are doing the work that makes everything else trustworthy.
The quality of an AI product is not determined only by what the model can do. It is determined by whether the product makes the limits of that intelligence impossible to misunderstand.
Enjoyed this Article?
Subscribe to Lean Product Growth for regular updates on building and scaling a successful product organization. Insights, strategies, and actionable tips—delivered straight to your inbox.